-
[논문 리뷰] VoxelNet논문 스터디 2023. 8. 26. 17:17
어디까지나 뇌피셜인 블로그
reference : https://arxiv.org/abs/1711.06396
VoxelNet은 lidar 만 사용하여 voxel 기반으로 3D object detection 하는 모델이다. 최근 많은 3D object detection 논문들이 point based가 아닌 voxel based이고 그중 대부분이 SECOND를 사용한다. 따라서 그 기반이 된 논문인 VoxelNet을 먼저 리뷰해보고자 한다.
Introduction
이 논문은 voxel $($volume + pixel$)$ 을 사용하여 pointcloud의 high computation and memory requirement 를 해결하려 한다.
voxel feature encoding 방법을 통해 interpoint interaction within voxel 을 가능케 하고, multiple VFE layer로 local 3D shape information의 complex feature를 학습하도록 한다.

VoxelNet Architecture
Feature Learning Network
VoxelNet은 3개의 block 으로 나뉘는데, 그중 첫번째 feature learning network이다. Feature learning network에서는 voxel partition, grouping, random sampling, stacked voxel feature encoding을 한다.
Voxel partition
주어진 pointcloud에 대해서 3D space를 나눠줄 것인데 each voxel size 가 range $D, H, W$에서 $v_D, v_H, v_W$ 를 가진다고 하자. 그럼 3D voxel grid는 $D'=D/v_D, H'=H/v_H, W'=W/v_W$ 의 사이즈로 나오게 된다.

Grouping
voxel 안에 들어갈 point를 grouping한다. distance, occlusion, object's relative pose, non-uniform sampling 때문에, lidar point cloud는 sparse하고 highly variable point density throughout the space 를 가진다. 따라서, grouping을 하면 voxel은 variable number 의 point를 갖게 된다.
voxel grid 안에 있는 point들을 grouping을 하는 이유는 voxel 자체의 feature를 가져오는게 아니라 나중에 VFE layer에서 pointwise feature로부터 voxelwise feature를 얻기 때문인 것 같다. VFE layer의 input이 grouping된 points 이고 output은 pointwise feature와 elementwise maxpool된 local aggregated feature의 concat이다.
voxel grid를 기준으로 point를 clipping만 하면 되는데 굳이 grouping 한다고 표현한 이유는 뭘까? 코드를 보면 해결 될 것 같다.
Random Sampling
high definition LiDAR point cloud는 ~100k point를 갖는다. 모든 points를 directly processing 하는 방법은 memory, efficiency 에 burden이 된다. 또한 highly variable point density throughout the space는 detection에 bias가 될 것이다. point가 많은 쪽에 더 detection이 많이 될 것이므로 bias가 생긴다고 하는 것 같다.
그래서 본 논문은 fixed number points $T$ 를 random sampling 한다. 즉, $T$ points 보다 더 많이 points를 가지는 voxel들에서 $T$ 개의 points를 random sampling 한다. 이 전략은 computational saving이 있고 voxel간의 points imbalance를 감소시켜준다. 따라서 sampling bias를 줄이고 training에 variation을 더한다고 한다.
imbalance를 줄이면 training의 variation은 왜 생기지?
Stacked Voxel Feature Encoding
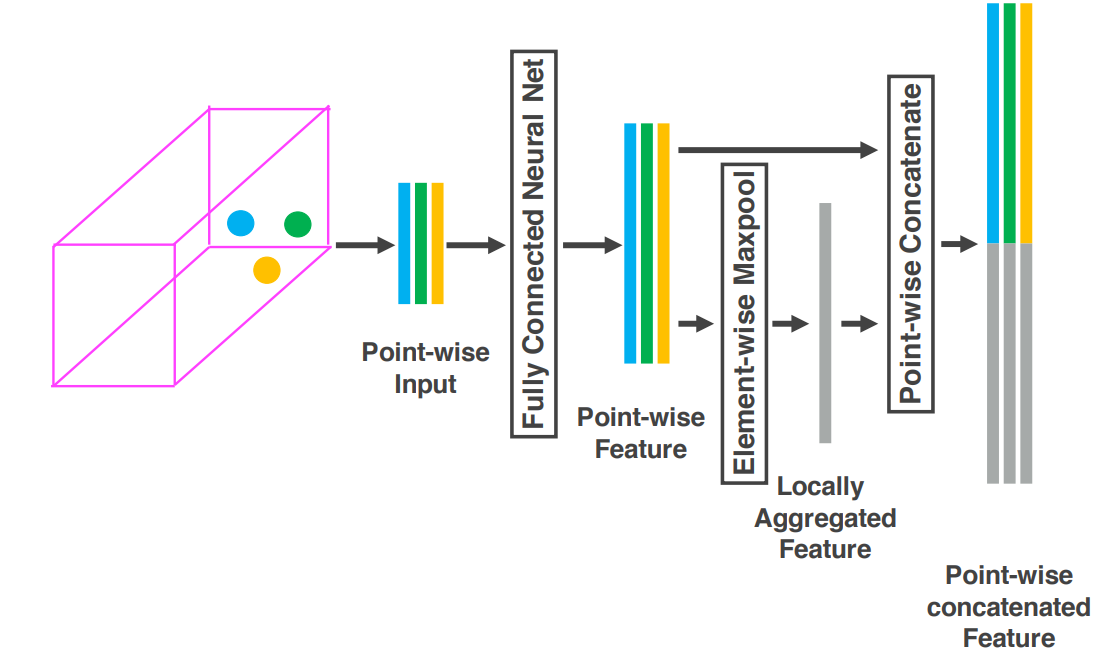
Voxel feature encoding layer 위의 그림은 stacked VFE $($voxel feature encoding$)$ layer의 첫번째 layer 를 나타낸다. 한 voxel안에 있는 points는 fully connected layer를 지나 point wise feature가 되고, 이를 elementwise maxpool 한 local aggregated feature와 concat한다. raw input은 즉 $V = \{p_i = [x_i, y_i, z_i, r_i]^T \in \mathbb{R}^4 \}_{i = 1,...,t} $, 여기서 $r_i$는 received refelectance이다. fully connected layer의 input은 voxel의 centroid를 뺀 offset을 추가한 $V_{in} = {\{ \hat{p}_i = {[x_i, y_i, z_i, r_i, x_i-v_x, y_i-v_y, z_i-v_z]}^T \in \mathbb{R}^7 \}}_{i=1...t}$ 이다. 각 $\hat{p}_i$는 voxel안에 shape of the surface 를 encode하기 위해 fully connected layer에서 feature space로 transform된 point feature $ f_i \in \mathbb{R}^m $ 가 된다.
convolutional neural network가 이미지의 feature를 추출한다는 점은 알았지만, fully connected network가 정확히 어떤 역할을 하는지 몰랐어서 찾아보았다. 하지만 읽어봐도 무슨 말인지 아직 모르겠다.
참고 : https://stats.stackexchange.com/questions/182102/what-do-the-fully-connected-layers-do-in-cnns
이렇게 point-wise feature를 얻고난 다음, $f_i$에 element-wise MaxPooling을 적용하여 locally aggregated feature $\tilde{f} \in \mathbb{R}^m$ 을 얻는다. 여기서 눈여겨 볼 점은 input으로 $V_{in}$ 이 들어갔는데 $\tilde{f}$ 는 $V$에 대한 것이다.
그런데 내가 아는 MaxPooling은 local feature를 만들어낸다기보단 feature map patch의 maximum value를 calculate하여 feature map을 down sampling하는데, locally aggregated feature를 얻는다는 점이 이해가 가지 않았다. 그리고 element-wise Max Pooling이 일반 Max Pooling과 어떻게 다른지도 잘 모르겠다. 인터넷을 찾아보니, 나와 비슷한 의문점을 가진 사람들이 있었다.
이해를 해보자면.. $f_i$는 point-wise feature representation이고, $t$개의 $f_i$를 np.max 한 것이 $\tilde{f}$ vector가 되는 것이다. 그럼 이제 이해가 간다. 그래도 아직 신기한건, $\tilde{f}$는 그저 max를 취했을 뿐인데 locally aggregated feature 로 여겨지고 실제로 그게 동작한다는 것이다. concat 하지 않고 $\tilde{f}$ 만 써서 dimension을 줄여보는 실험을 해봐야겠다.참고 : https://stats.stackexchange.com/questions/398748/what-is-element-wise-max-pooling
그 다음엔 $f_i$ 와 $\tilde{f}$ 를 point-wise concatenate 한 feature를 만드는데, 그것이 ${{f_i}^{out}}^T \in \mathbb{R}^{2m}$이다. 이는 output feature set $V_{out} = {\{f^T_i\}}_{i...t}$ 이 된다. 모든 non-empty voxel은 same set of parameters 를 FCN에서 share한다.
그러면 다시 또 드는 의문점.. 왜 FCN에서 same set of parameter를 share하는가? 물론 다 다른 parameter를 쓰면 너무 큰 computational cost가 들 것 같다.
아무튼 VFE layer를 쌓아 input feature를 $c_{in}$ 에서 $c_{out}$으로 transform한다. linear layer는 $c_{in} \times c_{out}/2 $ size of matrix를, point-wise concatenation 은 $c_{out}$ dimension을 내뱉는다. output feature가 point-wise와 locally aggregated feature를 concat한 것이기 때문에 stacking VFE layer는 voxel 안의 point interaction을 encoding 하고 descriptive shape information을 학습할 수 있는 final feature representation을 만든다.
voxel feature들은 spatial coordinate을 가진 non-empty voxel이고, 얻은 list of voxel-wise feature 은 sparse 4D tensor로 represent 된다. pointcloud는 ~100k points들 중 90%가 sparse하기 때문에 non-empty voxel만 sparse tensor로 만드는 것이 메모리 및 computation cost를 매우 줄여준다. 이 방법이 voxelnet이 efficient한 critical step이라고 한다.
Convolutional Middle Layers
이 파트가 SECOND에서 많이 개선된 부분이다. VoxelNet에서는 Conv$M$D 라는 $M$-dimensional convolution operator를 사용하는데 SECOND에서는 sparse convolutional layer인 spconv를 사용하고 그 이후 논문들은 모두 spconv를 사용하게 되었다.
Region Proposal Network
RPN network도 특별한 부분은 없다. 비교적 최근 논문인 Transfusion에서 RPN을 두 단계로 나누어 inital resion proposal과 image guidance를 준 proposal을 받아 크게 성능을 향상시켰다. 그래서 SOTA인 BEVFusion 등에서도 Transfusion의 Detection Head를 거의 그대로 사용하였다.
리뷰를 마치며..
현 시점 기준 오래된 논문이기 때문에 experiment는 생략한다. voxel-based 3D object detection에 대한 기초적인 정보를 얻어서 유익한 논문이었다. 의문점도 물론 있지만 해결되면 다시 적어놓을 것이다. 또한 읽다보니 개선하고 싶은 부분이 생겨서 회의를 거쳐 실험을 해볼 예정이다.
'논문 스터디' 카테고리의 다른 글
[논문 리뷰] On Layer Normalization in the Transformer Architecture (0) 2023.09.24 [논문 리뷰] Understanding and Improving Layer Normalization (0) 2023.09.21 [논문리뷰] Do Bayesian Neural Networks Need To Be Fully Stochastic? (0) 2023.09.15 [논문 리뷰] Flatformer (0) 2023.07.05 [논문 리뷰] source free domain adaptation via distribution estimation (0) 2023.06.22